Online News Analysis - Predicting Media Shares by Article Characteristics ================ Matt Kasle 10/15/2020
wednesday articles
Introduction
This dataset summarizes a heterogeneous set of features about articles published by Mashable in a period of two years. The goal is to predict the number of shares in social networks (popularity).
There are 61 attributes, 58 which are predictive attributes, 2 of which are non-predictive (url and timestamp), and 1 that is the target.
The types of veriables include the number of words in the article, the number of words in the title, the positivity and sentimentality of the article, the article’s subject, the number of keywords used, and much more.
The objective of this project is to predict the number of social media shares using two different tree-based algorithms. The first algorithm will be a non-ensemble regression tree, and the second algorithm will be a boosted trees algorithm, which is a state-of-the-art classification technique.
The other objective of this project is to create an automated report that outputs the classification analysis for each articles published on each weekday.
The required packages to run this analysis are tidyverse, caret, tree, and patchwork.
Data
First, we need to read in the data and set up the subsetting of the data into a single weekday. Then, we’ll split the data set to a training and test set for training and evaluating the classificaiton models. A 70/30 train-test split will be used.
set.seed(1)
library(tidyverse)
library(caret)
library(tree)
news <- read_csv("OnlineNewsPopularity.csv")
varDayOfWeek <- parse(text=paste0("weekday_is_", params$day_of_week))
news <- news %>% filter(eval(varDayOfWeek) == 1)
news <- news %>% select(-url, -timedelta, -weekday_is_monday, -weekday_is_tuesday, -weekday_is_wednesday,
-weekday_is_thursday,-weekday_is_friday,
-weekday_is_saturday, -weekday_is_sunday, -is_weekend)
newsIndex <- createDataPartition(news$shares, p = 0.3, list = FALSE)
newsTrain <- news[newsIndex, ]
newsTest <- news[-newsIndex, ]
Summarizations
Below are summary statistics of the online news data set, such as the number of observations in the train set, a numerical summary of the response variable (number of social media shares), a distribution of the response, and relationships between the response and interesting variables in the dataset.
Number of rows in training set:
nrow(newsTrain)
## [1] 2232
Summary of response variable:
summary(newsTrain$shares)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 63.0 888.5 1300.0 3237.5 2600.0 205600.0
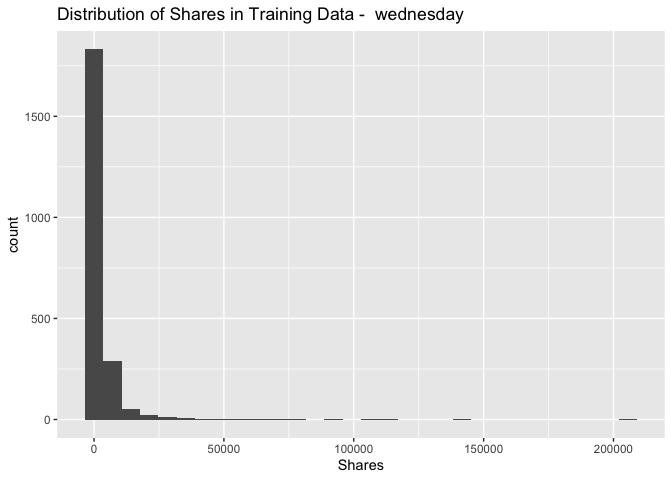
It is important to make note of the minimum and maximum of the response variable, as well as the median and quartiles. For future analysis, it may be best to remove outliers.
Distribution of response variable:
ggplot(data = newsTrain, aes(x = shares)) +
geom_histogram() + xlab("Shares") + ggtitle(paste("Distribution of Shares in Training Data - ",
params$day_of_week))
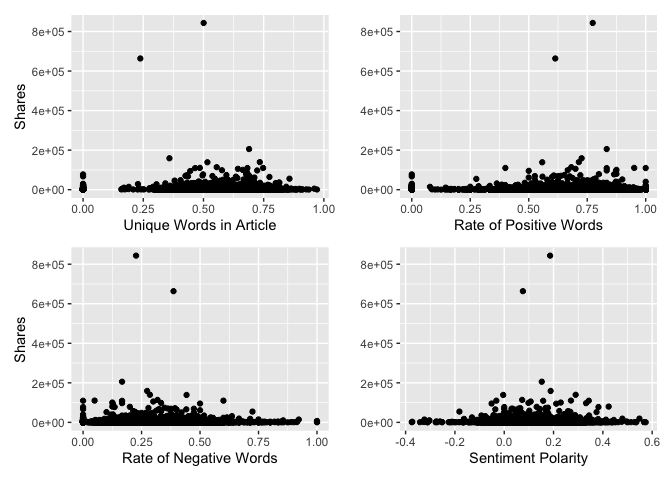
Below is a plot of four interesting variables to the response variable, shares. We want to see if there are any intersting patterns here.
library(patchwork)
par(mfrow=c(2,2))
plot1 <- ggplot(data=news, aes(x = news$n_unique_tokens, y = shares)) + geom_point(stat = "identity") +
labs(x="Unique Words in Article", y="Shares")
plot2 <- ggplot(data=news, aes(x = news$rate_positive_words, y = shares)) + geom_point(stat = "identity") +
labs(x="Rate of Positive Words", y="")
plot3 <- ggplot(data=news, aes(x = news$rate_negative_words, y = shares)) + geom_point(stat = "identity") +
labs(x="Rate of Negative Words", y="Shares")
plot4 <- ggplot(data=news, aes(x = news$global_sentiment_polarity, y = shares)) + geom_point(stat = "identity") +
labs(x="Sentiment Polarity", y="")
plot1 + plot2 + plot3 + plot4
## Warning: Use of `news$n_unique_tokens` is discouraged. Use `n_unique_tokens` instead.
## Warning: Use of `news$rate_positive_words` is discouraged. Use `rate_positive_words` instead.
## Warning: Use of `news$rate_negative_words` is discouraged. Use `rate_negative_words` instead.
## Warning: Use of `news$global_sentiment_polarity` is discouraged. Use `global_sentiment_polarity` instead.
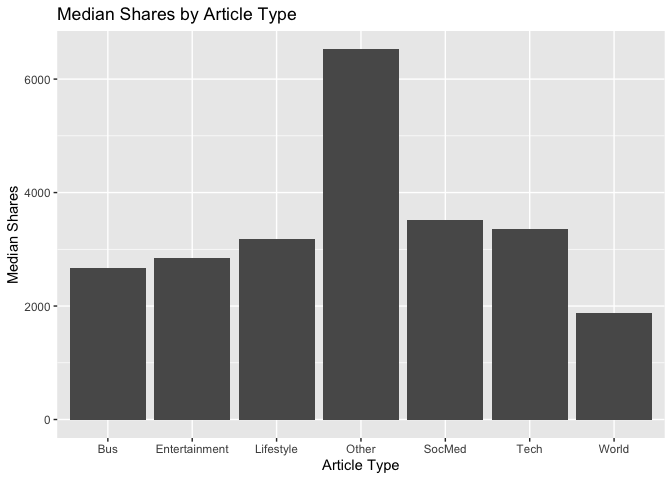
There are six different article subjects. It would be interesting to know if some subjects are more popular than others, so we can plot the median shares by the different article types.
news['article_type'] <- ifelse(news$data_channel_is_lifestyle == 1, "Lifestyle",
ifelse(news$data_channel_is_entertainment == 1, "Entertainment",
ifelse(news$data_channel_is_world == 1, "World",
ifelse(news$data_channel_is_bus == 1, "Bus",
ifelse(news$data_channel_is_socmed == 1, "SocMed",
ifelse(news$data_channel_is_tech == 1, "Tech","Other"))))))
ggplot(data=news, aes(x = article_type, y = shares)) + geom_bar(stat = "summary", fun.y = "median") +
labs(x="Article Type", y="Median Shares", title="Median Shares by Article Type")
## Warning: Ignoring unknown parameters: fun.y
## No summary function supplied, defaulting to `mean_se()`
# drop column used for plotting
news <- news %>% select(-article_type)
Modeling
There should be text describing the type of model you are fitting, your fitting process, and the final chosen model (this last part is to be automated so I don’t expect you to explicitly interpret that model, but you should be able to display something about the final model chosen on the training data).
Regression Tree Model
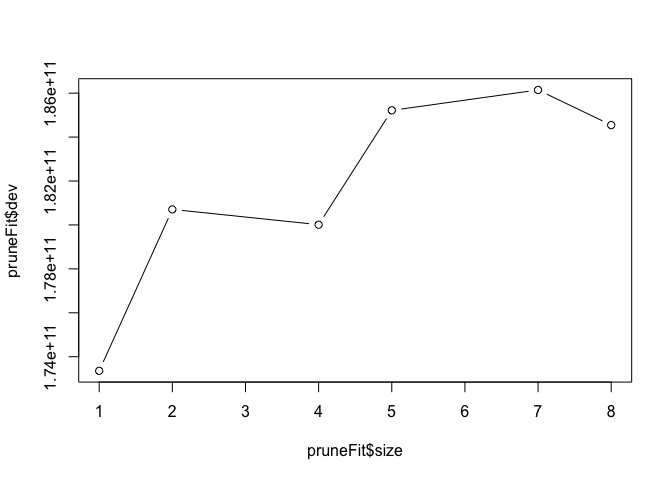
The first model fit to the data will be a regression tree. We’ll use leave-one-out cross-validation to determine the optimal size of the model, as defined by number of splits. By plotting the fitted tree, we can see the deviance by tree size (larger deviance means a better fit).
treeFit <- tree(shares ~ ., data = newsTrain)
summary(treeFit)
##
## Regression tree:
## tree(formula = shares ~ ., data = newsTrain)
## Variables actually used in tree construction:
## [1] "LDA_02" "kw_avg_avg" "global_subjectivity" "LDA_04"
## [5] "global_rate_positive_words" "LDA_01" "title_sentiment_polarity"
## Number of terminal nodes: 8
## Residual mean deviance: 59650000 = 1.327e+11 / 2224
## Distribution of residuals:
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -43340.0 -1880.0 -1427.0 0.0 -327.3 162800.0
pruneFit <- cv.tree(treeFit,
K=nrow(newsTrain)-1
)
pruneFitFinal <- prune.tree(treeFit, best = pruneFit$size[1])
plot(pruneFit$size ,pruneFit$dev ,type="b")
Boosted tree model
Next, we’ll fit a boosted regression tree. The boosted tree algorithm has a few hyperparameters, and we’ll use repeated 10-fold cross-validation to determine the optimal hyperparameter values. The hyperparameters of the optimal boosted tree is printed below, as well a summary of each fitted model.
fitControl <- trainControl(## 10-fold CV
method = "repeatedcv",
number = 10,
## repeated ten times
repeats = 5
)
boostedFit <- train(shares ~ ., data = newsTrain,
method = "gbm",
trControl = fitControl,
verbose = FALSE
)
boostedFit$bestTune
## n.trees interaction.depth shrinkage n.minobsinnode
## 4 50 2 0.1 10
boostedFit$results
## shrinkage interaction.depth n.minobsinnode n.trees RMSE Rsquared MAE RMSESD RsquaredSD MAESD
## 1 0.1 1 10 50 7873.222 0.03860796 3080.923 3506.441 0.03564400 508.2939
## 4 0.1 2 10 50 7841.102 0.05946575 3057.780 3449.896 0.05341130 520.1628
## 7 0.1 3 10 50 7869.420 0.05847293 3094.170 3404.068 0.05108486 502.8650
## 2 0.1 1 10 100 7945.589 0.04263726 3109.516 3428.004 0.03778949 497.4354
## 5 0.1 2 10 100 7949.284 0.05550493 3109.370 3379.641 0.05159126 512.4009
## 8 0.1 3 10 100 7969.152 0.05576963 3153.122 3353.237 0.04917912 517.6564
## 3 0.1 1 10 150 7978.183 0.04254558 3138.687 3402.417 0.03866204 498.8066
## 6 0.1 2 10 150 8018.657 0.05034314 3143.171 3345.425 0.04820599 497.4756
## 9 0.1 3 10 150 8044.023 0.05259325 3205.693 3342.064 0.04522950 515.0013
Linear regression model
Next, we’ll fit a multiple linear regression model on train data. Summary of the model is printed below.
linearfit<-lm(shares~.,data=newsTrain)
summary(linearfit)
##
## Call:
## lm(formula = shares ~ ., data = newsTrain)
##
## Residuals:
## Min 1Q Median 3Q Max
## -19041 -2262 -886 457 187712
##
## Coefficients: (2 not defined because of singularities)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -4.361e+03 2.790e+03 -1.563 0.118200
## n_tokens_title -3.568e+01 8.706e+01 -0.410 0.682021
## n_tokens_content 8.011e-01 7.284e-01 1.100 0.271539
## n_unique_tokens 2.509e+03 5.806e+03 0.432 0.665678
## n_non_stop_words 6.179e+03 4.982e+03 1.240 0.215017
## n_non_stop_unique_tokens 3.070e+03 4.974e+03 0.617 0.537170
## num_hrefs 1.641e+01 2.218e+01 0.740 0.459405
## num_self_hrefs -8.728e+01 6.239e+01 -1.399 0.161961
## num_imgs 8.583e+00 3.079e+01 0.279 0.780453
## num_videos -2.005e+01 5.074e+01 -0.395 0.692772
## average_token_length -1.329e+03 7.300e+02 -1.821 0.068745 .
## num_keywords 2.139e+02 1.150e+02 1.861 0.062933 .
## data_channel_is_lifestyle -3.063e+03 1.254e+03 -2.444 0.014624 *
## data_channel_is_entertainment -2.162e+03 8.172e+02 -2.645 0.008231 **
## data_channel_is_bus -1.830e+03 1.187e+03 -1.542 0.123154
## data_channel_is_socmed -1.428e+03 1.223e+03 -1.168 0.243000
## data_channel_is_tech -1.511e+03 1.185e+03 -1.275 0.202548
## data_channel_is_world -1.864e+03 1.230e+03 -1.516 0.129790
## kw_min_min 8.452e+00 5.143e+00 1.643 0.100452
## kw_max_min 5.575e-01 2.817e-01 1.979 0.047925 *
## kw_avg_min -3.122e+00 1.724e+00 -1.810 0.070357 .
## kw_min_max -2.075e-03 3.406e-03 -0.609 0.542545
## kw_max_max 6.550e-04 1.792e-03 0.365 0.714801
## kw_avg_max -6.453e-04 2.543e-03 -0.254 0.799707
## kw_min_avg -1.557e-02 2.402e-01 -0.065 0.948328
## kw_max_avg -2.656e-01 8.052e-02 -3.298 0.000988 ***
## kw_avg_avg 1.917e+00 4.647e-01 4.125 3.85e-05 ***
## self_reference_min_shares 9.569e-02 2.456e-02 3.896 0.000101 ***
## self_reference_max_shares -6.948e-04 1.146e-02 -0.061 0.951643
## self_reference_avg_sharess 1.738e-03 2.736e-02 0.064 0.949365
## LDA_00 9.420e+02 1.383e+03 0.681 0.495854
## LDA_01 -1.273e+03 1.605e+03 -0.793 0.427827
## LDA_02 4.618e+02 1.412e+03 0.327 0.743662
## LDA_03 -1.891e+02 1.500e+03 -0.126 0.899698
## LDA_04 NA NA NA NA
## global_subjectivity 5.228e+02 2.559e+03 0.204 0.838146
## global_sentiment_polarity 8.860e+03 4.918e+03 1.802 0.071738 .
## global_rate_positive_words -1.960e+04 2.157e+04 -0.909 0.363447
## global_rate_negative_words 3.501e+04 4.232e+04 0.827 0.408158
## rate_positive_words -2.147e+03 3.473e+03 -0.618 0.536570
## rate_negative_words NA NA NA NA
## avg_positive_polarity -5.320e+03 4.060e+03 -1.310 0.190220
## min_positive_polarity -2.291e+03 3.289e+03 -0.697 0.486091
## max_positive_polarity 7.235e+02 1.315e+03 0.550 0.582224
## avg_negative_polarity -2.330e+03 3.825e+03 -0.609 0.542385
## min_negative_polarity 1.980e+02 1.438e+03 0.138 0.890515
## max_negative_polarity -6.699e+02 3.164e+03 -0.212 0.832335
## title_subjectivity 7.527e+02 8.346e+02 0.902 0.367215
## title_sentiment_polarity 1.714e+03 7.561e+02 2.267 0.023516 *
## abs_title_subjectivity 7.041e+02 1.112e+03 0.633 0.526651
## abs_title_sentiment_polarity 7.621e+02 1.195e+03 0.638 0.523760
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 8274 on 2183 degrees of freedom
## Multiple R-squared: 0.0914, Adjusted R-squared: 0.07143
## F-statistic: 4.575 on 48 and 2183 DF, p-value: < 2.2e-16
Model Evaluations
Finally, we’ll evaluate the performance of each model by seeking the lowest root mean squared error of its predictions on the test dataset when compared to the actual values in the dataset. This should be a good approximation of the model’s performance on unseen data.
Regression Tree
Below is the RMSE of the optimal (non-ensemble) regression tree:
treePred <- predict(pruneFitFinal, newdata = dplyr::select(newsTest, -shares))
sqrt(mean((treePred-newsTest$shares)^2))
## [1] 16750.51
Boosted Trees
Below is the RMSE of the optimal boosted regression tree:
boostedTreePred <- predict(boostedFit, newdata = dplyr::select(newsTest, -shares))
sqrt(mean((boostedTreePred-newsTest$shares)^2))
## [1] 16576.92
linear regression
Below is the RMSE of the multiple linear model:
linearPred<-predict(linearfit, newdata=dplyr::select(newsTest, -shares))
sqrt(mean((linearPred-newsTest$shares)^2))
## [1] 16544.58